Установка MediaPipe на Raspberry Pi – пример распознавания жестов
Это руководство представляет собой введение в библиотеку MediaPipe Python на плате Raspberry Pi. Оно охватывает установку MediaPipe с помощью pip в виртуальном окружении и запуск примера распознавания жестов.
MediaPipe – это кроссплатформенный фреймворк для построения пайплайнов пользовательских решений машинного обучения (ML) для потоковых медиа (живое видео). Фреймворк MediaPipe был открыт Google и в настоящее время доступен в раннем релизе.

Необходимые условия
Перед тем как продолжить:
Вам нужна плата Raspberry Pi и USB-камера.
У вас должна быть Raspberry Pi с установленной Raspberry Pi OS (32-битная или 64-битная).
Вы должны уметь :doc:`устанавливать подключение к удаленному рабочему столу с вашей Raspberry Pi </raspberry/rnt/raspberry-pi-remote-desktop-connection-rdp-windows/index>`_ – :doc:`нажмите здесь для инструкций для Mac OS </raspberry/rnt/raspberry-pi-remote-desktop-connection-rdp-mac-os/index>`_.
У вас должен быть :doc:`установлен OpenCV на вашей Raspberry Pi </raspberry/rnt/install-opencv-raspberry-pi/index>`_.
В наших проектах Raspberry Pi с камерой мы будем использовать обычную USB-камеру Logitech, как показано на фотографии ниже.

MediaPipe
MediaPipe – это кроссплатформенный фреймворк с открытым исходным кодом для построения пайплайнов выполнения приложений компьютерного зрения, построенный поверх TensorFlow Lite.
MediaPipe абстрагировал сложности настройки ML на устройстве, сделав его настраиваемым, готовым к продакшену и доступным на разных платформах. Используя MediaPipe, вы можете использовать простой API, который получает входное изображение и выводит результат предсказания.
Пример жеста руки
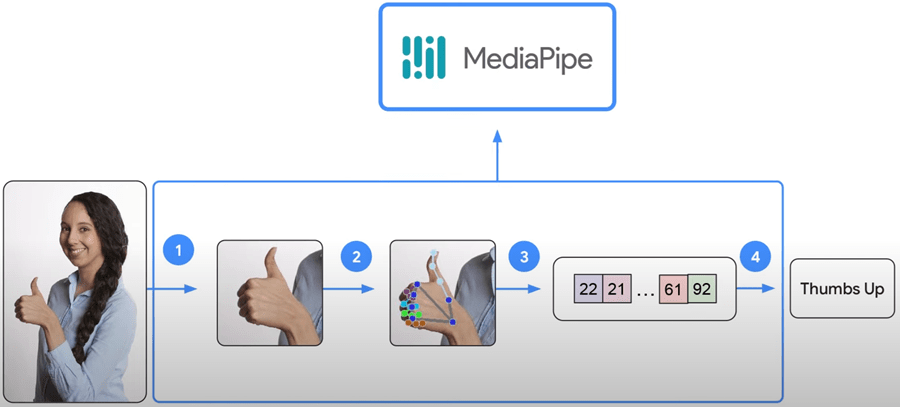
Вход: изображение человека, делающего жест «большой палец вверх»
MediaPipe выполняет всю тяжелую работу за вас:
Определяет, есть ли рука на предоставленном изображении;
Затем определяет ключевые точки руки;
Создает вектор вложений жестов.
Выход: классифицирует изображение на основе предоставленной модели (определяет жест «большой палец вверх»).
Подводя итог, вот ключевые особенности MediaPipe:
Решение для машинного обучения (ML) на устройстве с простыми в использовании абстракциями.
Легковесные модели ML при сохранении точности.
Специализированная обработка для различных областей, включая зрение, текст и аудио.
Использует API с минимальным количеством кода или студию без кода для настройки, оценки, прототипирования и развертывания.
Сквозная оптимизация, включая аппаратное ускорение, при этом достаточно легковесная для работы на устройствах с батарейным питанием.
Установка MediaPipe на Raspberry Pi с помощью pip в виртуальном окружении (рекомендуется)
Имея подключение к удаленному рабочему столу с вашей Raspberry Pi, обновите и улучшите вашу Raspberry Pi, если доступны какие-либо обновления. Выполните следующую команду:
sudo apt update && sudo apt upgrade -y
Создание виртуального окружения
Мы уже :doc:`установили библиотеку OpenCV в виртуальном окружении в предыдущем руководстве </raspberry/rnt/install-opencv-raspberry-pi/index>`_. Нам нужно установить библиотеку MediaPipe в том же виртуальном окружении.
Введите следующую команду в окне терминала, чтобы перейти в каталог Projects на Рабочем столе:
cd ~/Desktop/projects
Затем вы можете выполнить следующую команду, чтобы проверить, что виртуальное окружение существует.
ls -l
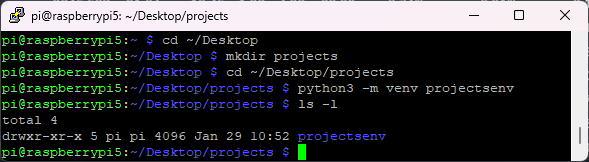
Активируйте виртуальное окружение projectsenv, которое было ранее создано при установке OpenCV:
source projectsenv/bin/activate
Ваша командная строка должна измениться, чтобы указать, что вы теперь находитесь в виртуальном окружении.

Установка библиотеки MediaPipe
Теперь, когда мы находимся в нашем виртуальном окружении, мы можем установить библиотеку MediaPipe. Выполните следующую команду:
pip3 install mediapipe
Через несколько секунд библиотека будет установлена (игнорируйте любые желтые предупреждения об устаревших пакетах).
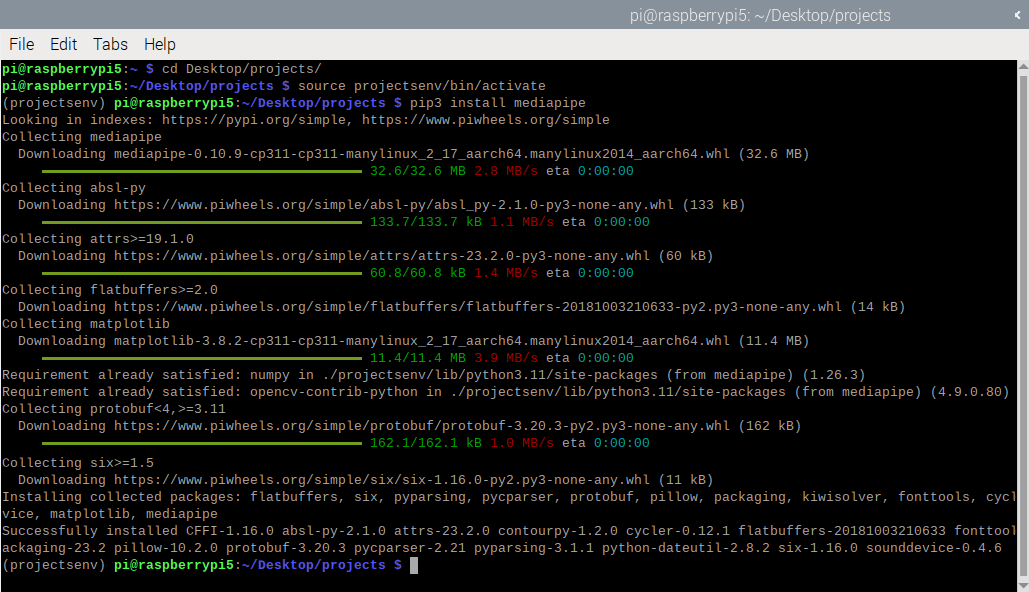
У вас все готово, чтобы начать писать код на Python и тестировать пример распознавания жестов.
Пример MediaPipe – распознавание жестов с Raspberry Pi
После установки MediaPipe мы запустим пример кода, который выполняет распознавание жестов. Этот скрипт распознает жесты рук на изображении или в видеоформате. Модель по умолчанию может распознавать семь различных жестов одной или двумя руками:
Большой палец вверх
Большой палец вниз
Знак победы (Victory)
Указательный палец вверх
Поднятый кулак
Открытая ладонь
Жест «Люблю тебя» (Love-You)
Эта конкретная модель была создана Google и прошла их строгие стандарты ML Fairness и готова к использованию в продакшене.
Распознавание жестов – скрипт Python
Клонируйте репозиторий GitHub на вашу Raspberry Pi с помощью команды git:
git clone https://github.com/RuiSantosdotme/mediapipe.git
Перейдите в каталог mediapipe/raspberry_pi_gesture_recognizer:
cd mediapipe/raspberry_pi_gesture_recognizer
Используйте команду ls, чтобы увидеть, есть ли у вас файлы, показанные на скриншоте ниже:
ls
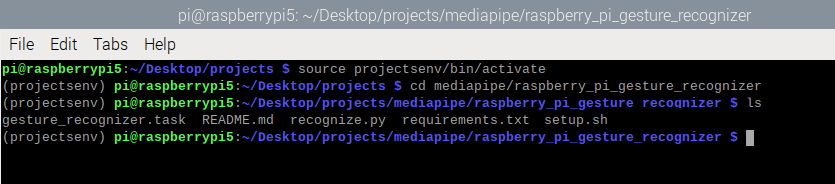
Наконец, введите команду для установки всех недостающих зависимостей:
sh setup.sh
# Полная информация о проекте на https://RandomNerdTutorials.com/install-mediapipe-raspberry-pi/
# Copyright 2023 The MediaPipe Authors. All Rights Reserved. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
# Main scripts to run gesture recognition.
import argparse
import sys
import time
import cv2
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
from mediapipe.framework.formats import landmark_pb2
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
# Global variables to calculate FPS
COUNTER, FPS = 0, 0
START_TIME = time.time()
def run(model: str, num_hands: int,
min_hand_detection_confidence: float,
min_hand_presence_confidence: float, min_tracking_confidence: float,
camera_id: int, width: int, height: int) -> None:
"""Continuously run inference on images acquired from the camera.
Args:
model: Name of the gesture recognition model bundle.
num_hands: Max number of hands can be detected by the recognizer.
min_hand_detection_confidence: The minimum confidence score for hand
detection to be considered successful.
min_hand_presence_confidence: The minimum confidence score of hand
presence score in the hand landmark detection.
min_tracking_confidence: The minimum confidence score for the hand
tracking to be considered successful.
camera_id: The camera id to be passed to OpenCV.
width: The width of the frame captured from the camera.
height: The height of the frame captured from the camera.
"""
# Start capturing video input from the camera
cap = cv2.VideoCapture(camera_id)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
# Visualization parameters
row_size = 50 # pixels
left_margin = 24 # pixels
text_color = (0, 0, 0) # black
font_size = 1
font_thickness = 1
fps_avg_frame_count = 10
# Label box parameters
label_text_color = (255, 255, 255) # white
label_font_size = 1
label_thickness = 2
recognition_frame = None
recognition_result_list = []
def save_result(result: vision.GestureRecognizerResult,
unused_output_image: mp.Image, timestamp_ms: int):
global FPS, COUNTER, START_TIME
# Calculate the FPS
if COUNTER % fps_avg_frame_count == 0:
FPS = fps_avg_frame_count / (time.time() - START_TIME)
START_TIME = time.time()
recognition_result_list.append(result)
COUNTER += 1
# Initialize the gesture recognizer model
base_options = python.BaseOptions(model_asset_path=model)
options = vision.GestureRecognizerOptions(base_options=base_options,
running_mode=vision.RunningMode.LIVE_STREAM,
num_hands=num_hands,
min_hand_detection_confidence=min_hand_detection_confidence,
min_hand_presence_confidence=min_hand_presence_confidence,
min_tracking_confidence=min_tracking_confidence,
result_callback=save_result)
recognizer = vision.GestureRecognizer.create_from_options(options)
# Continuously capture images from the camera and run inference
while cap.isOpened():
success, image = cap.read()
if not success:
sys.exit(
'ERROR: Unable to read from webcam. Please verify your webcam settings.'
)
image = cv2.flip(image, 1)
# Convert the image from BGR to RGB as required by the TFLite model.
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=rgb_image)
# Run gesture recognizer using the model.
recognizer.recognize_async(mp_image, time.time_ns() // 1_000_000)
# Show the FPS
fps_text = 'FPS = {:.1f}'.format(FPS)
text_location = (left_margin, row_size)
current_frame = image
cv2.putText(current_frame, fps_text, text_location, cv2.FONT_HERSHEY_DUPLEX,
font_size, text_color, font_thickness, cv2.LINE_AA)
if recognition_result_list:
# Draw landmarks and write the text for each hand.
for hand_index, hand_landmarks in enumerate(
recognition_result_list[0].hand_landmarks):
# Calculate the bounding box of the hand
x_min = min([landmark.x for landmark in hand_landmarks])
y_min = min([landmark.y for landmark in hand_landmarks])
y_max = max([landmark.y for landmark in hand_landmarks])
# Convert normalized coordinates to pixel values
frame_height, frame_width = current_frame.shape[:2]
x_min_px = int(x_min * frame_width)
y_min_px = int(y_min * frame_height)
y_max_px = int(y_max * frame_height)
# Get gesture classification results
if recognition_result_list[0].gestures:
gesture = recognition_result_list[0].gestures[hand_index]
category_name = gesture[0].category_name
score = round(gesture[0].score, 2)
result_text = f'{category_name} ({score})'
# Compute text size
text_size = \
cv2.getTextSize(result_text, cv2.FONT_HERSHEY_DUPLEX, label_font_size,
label_thickness)[0]
text_width, text_height = text_size
# Calculate text position (above the hand)
text_x = x_min_px
text_y = y_min_px - 10 # Adjust this value as needed
# Make sure the text is within the frame boundaries
if text_y < 0:
text_y = y_max_px + text_height
# Draw the text
cv2.putText(current_frame, result_text, (text_x, text_y),
cv2.FONT_HERSHEY_DUPLEX, label_font_size,
label_text_color, label_thickness, cv2.LINE_AA)
# Draw hand landmarks on the frame
hand_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
hand_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y,
z=landmark.z) for landmark in
hand_landmarks
])
mp_drawing.draw_landmarks(
current_frame,
hand_landmarks_proto,
mp_hands.HAND_CONNECTIONS,
mp_drawing_styles.get_default_hand_landmarks_style(),
mp_drawing_styles.get_default_hand_connections_style())
recognition_frame = current_frame
recognition_result_list.clear()
if recognition_frame is not None:
cv2.imshow('gesture_recognition', recognition_frame)
# Stop the program if the ESC key is pressed.
if cv2.waitKey(1) == 27:
break
recognizer.close()
cap.release()
cv2.destroyAllWindows()
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
'--model',
help='Name of gesture recognition model.',
required=False,
default='gesture_recognizer.task')
parser.add_argument(
'--numHands',
help='Max number of hands that can be detected by the recognizer.',
required=False,
default=1)
parser.add_argument(
'--minHandDetectionConfidence',
help='The minimum confidence score for hand detection to be considered '
'successful.',
required=False,
default=0.5)
parser.add_argument(
'--minHandPresenceConfidence',
help='The minimum confidence score of hand presence score in the hand '
'landmark detection.',
required=False,
default=0.5)
parser.add_argument(
'--minTrackingConfidence',
help='The minimum confidence score for the hand tracking to be '
'considered successful.',
required=False,
default=0.5)
# Finding the camera ID can be very reliant on platform-dependent methods.
# One common approach is to use the fact that camera IDs are usually indexed sequentially by the OS, starting from 0.
# Here, we use OpenCV and create a VideoCapture object for each potential ID with 'cap = cv2.VideoCapture(i)'.
# If 'cap' is None or not 'cap.isOpened()', it indicates the camera ID is not available.
parser.add_argument(
'--cameraId', help='Id of camera.', required=False, default=0)
parser.add_argument(
'--frameWidth',
help='Width of frame to capture from camera.',
required=False,
default=640)
parser.add_argument(
'--frameHeight',
help='Height of frame to capture from camera.',
required=False,
default=480)
args = parser.parse_args()
run(args.model, int(args.numHands), args.minHandDetectionConfidence,
args.minHandPresenceConfidence, args.minTrackingConfidence,
int(args.cameraId), args.frameWidth, args.frameHeight)
if __name__ == '__main__':
main()
Демонстрация распознавания жестов
Активировав виртуальное окружение, выполните следующую команду:
python recognize.py --cameraId 0 --model gesture_recognizer.task --numHands 2
Вы должны ввести правильный номер ID камеры для вашей USB-камеры, в моем случае это 0, но вам может потребоваться изменить его. Вы можете найти больше информации о поддерживаемых параметрах в документации.
С запущенным примером делайте различные жесты перед камерой. Она будет определять и идентифицировать жесты (из списка жестов, которые мы видели ранее). Она может определять жесты одной или двух рук одновременно.
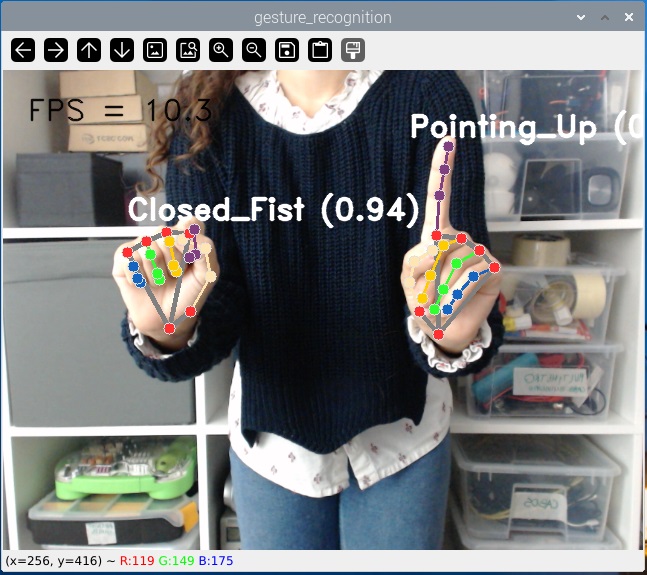

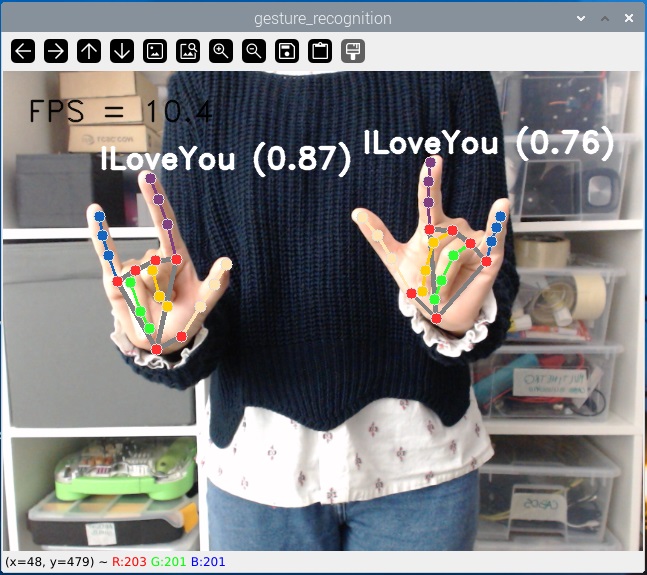
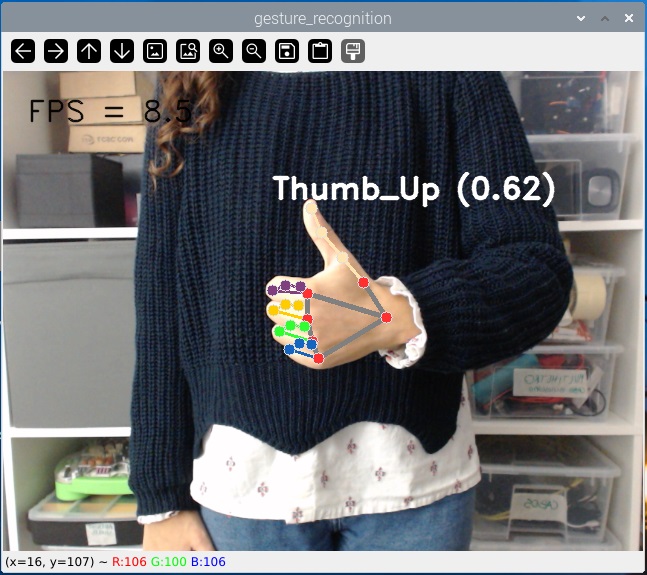
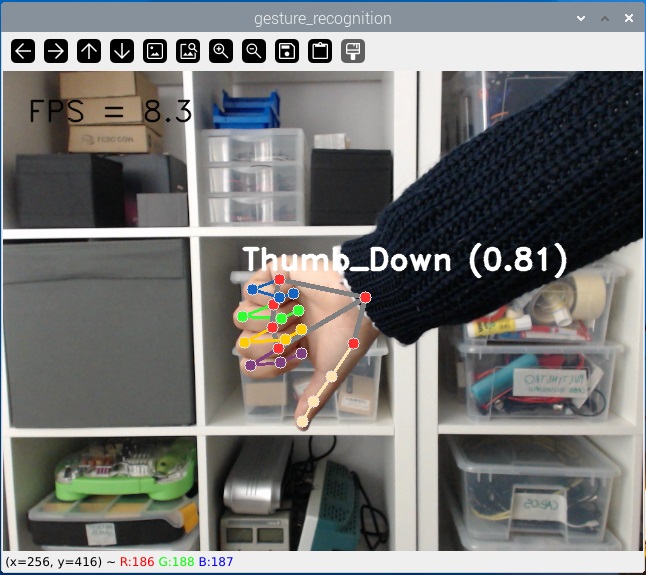
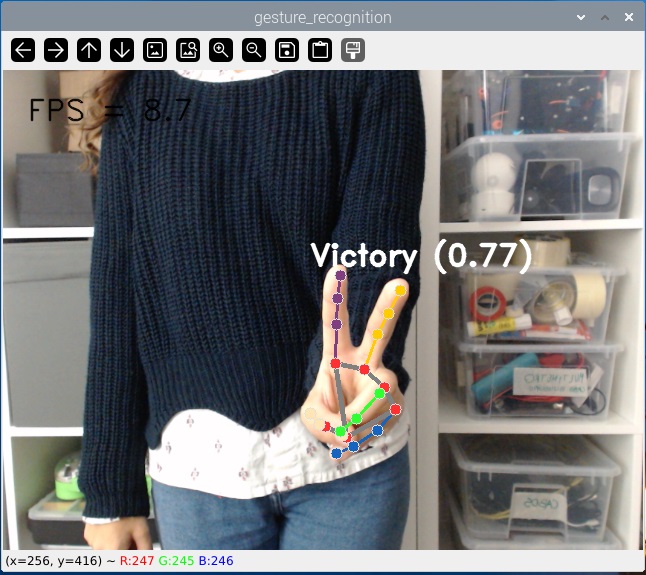
Вы также можете посмотреть следующую видео-демонстрацию:
Заключение
Это руководство было кратким введением в MediaPipe с Raspberry Pi. MediaPipe – это простой в использовании фреймворк, который позволяет создавать проекты машинного обучения.
В этом руководстве мы протестировали пример распознавания жестов рук. MediaPipe также имеет другие интересные примеры, например, подсчет количества поднятых пальцев на руке. Это может быть особенно полезно в проектах автоматизации, потому что позволяет управлять чем-либо с помощью жестов. Например, включать определенный GPIO Raspberry Pi, когда вы поднимаете один палец, и выключать его, когда вы поднимаете два пальца. Возможности безграничны.
Мы надеемся, что это руководство показалось вам интересным.
Если наши читатели проявят достаточный интерес к подобной тематике, мы планируем создать больше проектов машинного обучения с использованием MediaPipe.
Если вы хотите узнать больше о Raspberry Pi, ознакомьтесь с нашими руководствами: